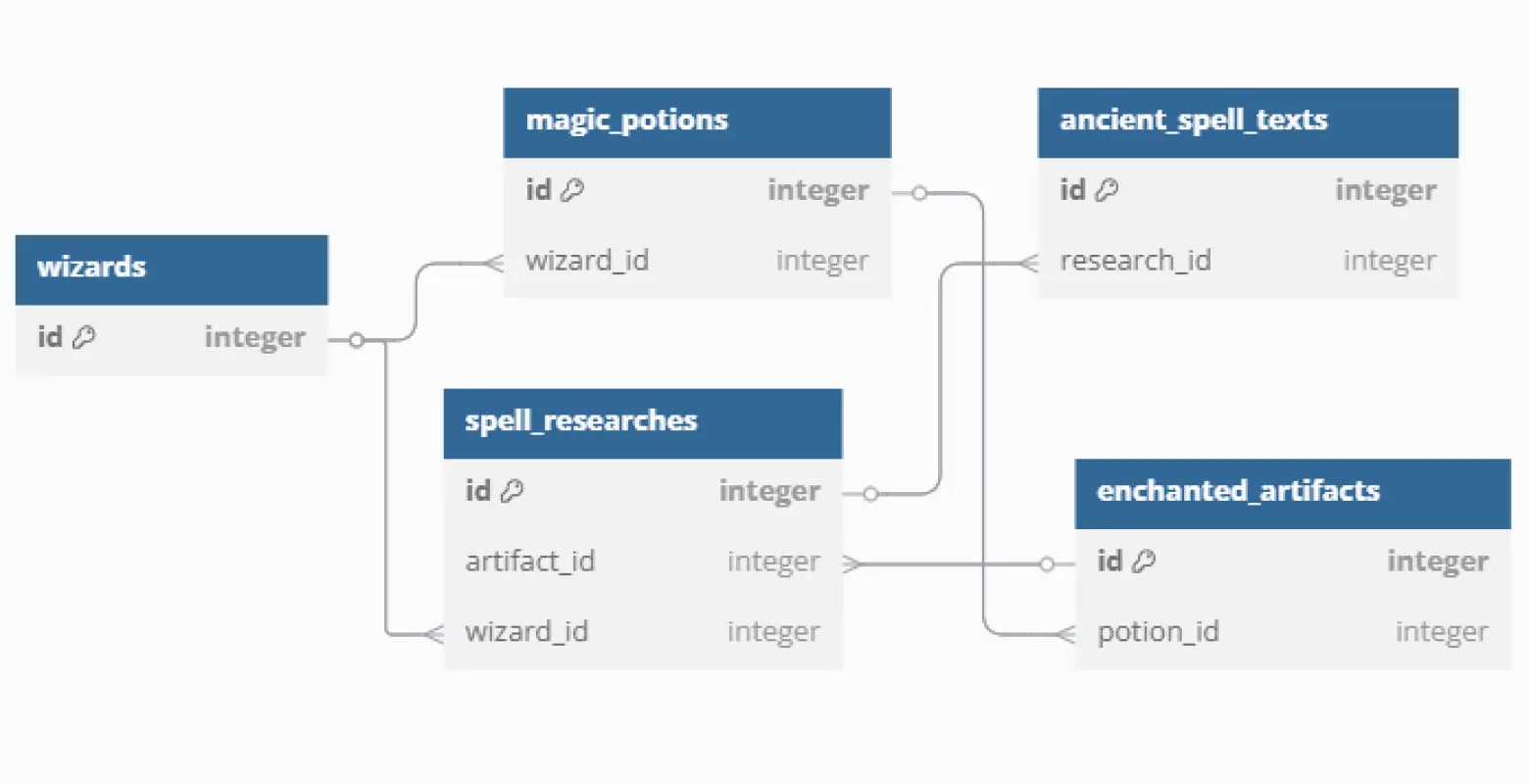
“Wat een mooi database-diagram, hè?”, vroeg ik trots aan mijn collega.
“Ja, heel mooi”, reageerde hij.
“Maar wij werken hier in PascalCase. Dus als je het nog even om zou kunnen zetten?”

Uitgebeeld: links mijn collega, rechts ik, na het worst case nieuws.
Code omtoveren naar de juiste case
Wanneer programmeurs code schrijven, kunnen ze kiezen uit verschillende manieren om woorden in samengestelde termen te structureren. Ik had mijn diagrammen gemaakt in snake_case, maar ze moesten worden omgezet naar PascalCase. In snake_case worden woorden gescheiden door underscores (_) en heeft alles kleine letters, terwijl PascalCase elk nieuw woord met een hoofdletter begint en de scheidingstekens weglaat.
Bijvoorbeeld:
spell_researches.wizard_id moet worden omgezet naar SpellResearches.WizardId.
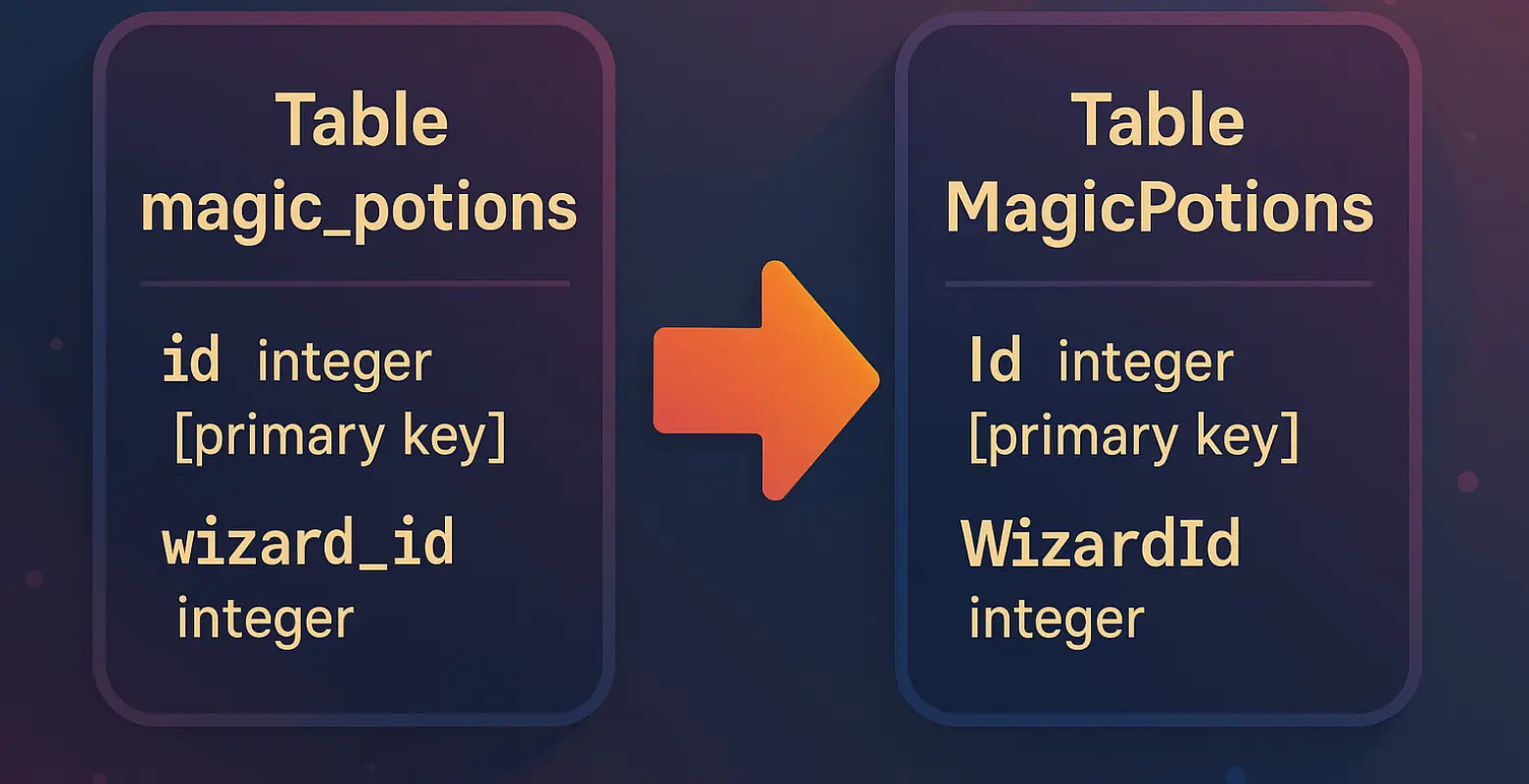
Ter illustratie: een voorbeeld van het omzetten van snake_case naar PascalCase. Onze echte database ging natuurlijk niet over tovenaars en tovenaarsspreuken. In werkelijkheid was het echte database diagram ook een stuk groter dan het voorbeeld uit de afbeelding waar dit artikel mee begon. Neem maar van mij aan: het zou een hoop werk worden om dit om te gaan zetten.
AI to the rescue
Nadat ik uitgehuild was, begon ik met het aanpassen van mijn tabellen en velden. Maar na de derde aanpassing bedacht ik mij: wat ben ik nu eigenlijk aan het doen? Dit kan AI toch heel simpel?
Eén vraag aan ChatGPT later en ik was de trotse eigenaar van een PascalCase database-diagram!
Maar dit is toch bijzonder. Ondanks dat ik:
- de hele dag door gebruik maak van LLM's
- meer Perplexity gebruik dan Google
- dagelijks tientallen afbeeldingen genereer met MidJourney en Dalle-3
- en regelmatig LLM-API's gebruik (zowel professioneel als hobbymatig) \
duurde het alsnog even voordat het lampje ging branden (dat ik deze taak niet zelf meer hoef te doen).
Blijkbaar zal het, dankzij de vele jaren die ik heb gewerkt zonder AI-technologie, nog wel even duren voordat ik al mijn oude gewoontes heb verleerd. En naarmate meer en meer software LLM-integratie krijgt, zal dit ook vanzelfsprekender worden.
Maar hoe vanzelfsprekend is het nu, op dit moment, onder de professionals? De collega's die ik het vroeg gaven toe dat ook zij niet direct hier aan hadden gedacht.
Dagdroom over toekomstige personalisatie
Ik besloot om de tijd die ik dankzij ChatGPT had bespaard op typwerk nuttig te besteden: ik ging dagdromen. Want stiekem (of misschien niet zo stiekem) is mijn voorkeur namelijk wel snake_case. Maar de (incorrecte) voorkeur van andere programmeurs kan dus bijv PascalCase zijn, of wellicht iets heel anders, zoals kebab-case. Maar belangrijker dan mijn voorkeur is natuurlijk dat een code-base consistent is.
Maar is deze (handmatige) consistentie nog wel nodig, in de toekomst? Zodra LLM’s snel en alomtegenwoordig genoeg zijn, zou je in feite moeiteloos de output die een programmeur te zien krijgt just-in-time kunnen formatteren in het gewenste formaat. En dan bedoel ik niet alleen specifieke formatting van de meest voorkomende formaten, want veel IDE's hebben hier natuurlijk al ondersteuning voor. Maar dankzij de flexibiliteit van LLM's wordt bijna iedere stijl die je maar kunt bedenken mogelijk.
Dit roept natuurlijk nieuwe vraagstukken op, zoals privacy en data-gevoeligheid. Vooral wanneer we deze LLM's nog niet (snel) lokaal kunnen draaien. Maar dat is een ander probleem dat hopelijk ooit opgelost wordt, en in ieder geval niet waar dit artikel (of mijn dagdroom) over gaat.
Maar wacht eens even
Als we weer even teruggaan naar het oorspronkelijke probleem: hoe weet ik eigenlijk of de gegenereerde output van (in dit geval) ChatGPT 4o wel klopt? Iedereen heeft inmiddels wel de term hallucinatie voorbij horen komen.
In het volgende artikel in deze reeks ga ik daar dieper op in.